
Как изменить код вируса
Обновлено: 23.04.2024
Введение
Первый вопрос, который приходит на ум – что именно классифицирует макровирусы, как полиморфные? Большинство макро-вирусов очень примитивны и не относятся к полиморфным. Однако есть несколько более сложных экземпляров зашифрованных вирусов, некоторые из которых даже имеют полиморфное кодирование.
Ранние Ridiculo-морфы
Первым, еще детским, шагом к полиморфизму был Outlaw. Фактически, его даже нельзя назвать полноценным полиморфом. Сам вирусный код не изменялся ни на байт, менялось только название несущего макроса. Поэтому, Outlaw полиморфом не являлся, хотя его первоначально и отнесли именно к этому классу вирусов. Все дело в том, что ранние (преимущественно, WordBasic-основанные) защитные программы, созданные для борьбы с макровирусами, проверяли только имя макроса (примитивно, но именно так и обстояло дело!) и подобная смена названия макроса позволяла довольно долго водить за нос антивирусы. Позже, когда ранние антивирусы сменились более совершенными, проверяющими код или логику программы, обнаружилось, что Outlaw не является полиморфом, а относится к обычным, неморфическим макровирусам.
Вирусы, использующие вставки цифрового мусора
Далее последовал шаг, который и по сей день использует большинство вирусов - вставка всякого мусора в вирусный код. В самом простом случае, используется вставка строк, содержащих случайные комментарии. Семейство WM97.Class - хороший пример этой техники. В этих вирусах каждая линия макрокода заполнена случайными комментариями, обычно содержащими различные комбинации имени пользователя, даты, установленных принтеров и т.д. Вот пример подобного куска кода из зараженного файла:
Sub Document_Close()
'SiR DySTyKSDINFECTEDINFECTED.DOC5/22/2001 6:04: 06 AM
On Error Resume Next
'SiR DySTyKSDINFECTEDINFECTED.DOC5/22/2001 6:04:06 AM
Options.SaveNormalPrompt = 0
'SiR DySTyKSDINFECTEDINFECTED.DOC5/22/2001 6:04:06 AM
Options.ConfirmConversions = 0
А вот этот же фрагмент в другом зараженном файле:
Sub Document_Open()
'SiR DySTyKSDGOAT1GOAT1.DOC5/22/2001 6:04:16 AM
On Error Resume Next
'SiR DySTyKSDGOAT1GOAT1.DOC5/22/2001 6:04:16 AM
Options.SaveNormalPrompt = 0
'SiR DySTyKSDGOAT1GOAT1.DOC5/22/2001 6:04:16 AM
Options.ConfirmConversions = 0
Эта методика привела к совершенствованию антивирусов – в ответ на нее, в антивирусные сканеры была добавлена технология игнорирования строк-коментариев при просмотре кода.
С каждым шагом инфицирования запрашивался макрос FileSaveAs и вирус несколько видоизменял свой код. Добавлялись случайные числа в виде комментариев и добавлялись дополнительные пустые строки. Через несколько стадий макрос напоминал следующий фрагмент:
dlg.Format = 1
' 0.38007424142506
jqp$ = FileName$()
Loop While DjFeUOL2kkwJCIE6 ActiveDocument.Save
DwFNV1qyGsV4 = 187
For LU1VyC6 = 8 To 54 Step 3:
If dDGlb7 <> Rnd * 28 Then
Do
PjN7FDkGwkU7 = PjN7FDkGwkU7 + 6
Loop While PjN7FDkGwkU7 ActiveDocument.Close: TzLPGXn3lZ6 = 1
В дополнение к вышеописанному, в данном вирусе применилась достаточно революционная по тем временам новинка – в командах заменялось написание некоторых символов – с заглавных на строчные и наоборот. Ну и, к тому же, вирус использовал опыт предшественников и, особенно в первых модификациях, активно использовал вставку комментариев в код. Надо признать, что различные экземпляры данного вируса даже в одинаковых поколениях были крайне непохожи друг на друга. Вирус был достаточно успешным и распространенным, но только до тех пор, пока в антивирусах в процедурах нормализации кода не были учтены все применяемые новинки.
Здесь надо отметить, что хоть существовавшие к тому моменту традиционные технологии нормализации кода в большинстве случаев и не позволяли поимку полиморфных макровирусов, но иногда могли и сработать - в случае выделения характерных фрагментов. В частности, в нашем примере, программистам требовалось бы декомпилировать код и выделить фрагменты вируса из остального месива мусора и частей других программ. Затем требовалось бы запустить процесс размножения и изучить изменение строк кода с каждым шагом, после чего запустить анализатор кода и выявить во всех копиях вируса из всего несущественного цифрового хлама следующие строки
Все, этого было бы достаточно для сканеров и подсчета контрольных сумм. Но, как вы, конечно, понимаете, это – отнюдь не быстрый процесс, и могло пройти несколько недель (а то и месяцев!), прежде чем был бы выявлен уникальный, характерный для данного макровируса отпечаток кода. И все это время вирус абсолютно беспрепятственно размножался бы по всей планете.
Code Collectors
Вскоре вирусы научились генерировать не только случайный цифровой мусор, но и части собственного значимого вирусного кода. Этот тип вирусов известен как Code Collectors. Примером такого типа вирусов может служить вирус Hope.AF. Его особенностью являлась способность альтернативной замены собственных фрагментов – функций и переменных. К примеру, объект ActiveDocument мог быть представлен в теле вируса случайным образом несколькими способами:
При каждом копировании производился случайный выбор одного из вариантов:
Фактически, логика программы от этого не менялась, происходили лишь небольшие, но многочисленные флуктуации относительного первоначального варианта. Но именно это и не позволяло привести код в единый нормальный вид или выделить характерную строку (хотя, в нашем примере можно выделить длинный фрагмент, но для этого необходимо предварительно провести декомпиляцию).
Вирусы данного класса являлись интересной разработкой, требующей от разработчиков антивирусных программ немалых затрат времени и ресурсов. Но, в итоге, все рано в каждом конкретном случае находились достаточно длинные фрагменты, пригодные для CRC-детектора.
Статичное кодирование
Наверное, читая эту статью и встречая описания различных способов изменения кода, вы уже сами обдумали этот самый очевидный вариант изменения кода – шифрование. Действительно, вся история полиморфных вирусов неразрывно связана с кодированием. Еще в славную эпоху седых 286-ых и 386-ых компьютеров кодированные полиморфы уже вовсю бегали по планете.
Конечно, мысль о кодированных макровирусах пришла в голову не только вам. Многие макровирусы используют статичное шифрование частей вирусного кода, применяя для этого, как правило, какой-нибудь простенький алгоритм (XOR или Shift). Ключ шифрования может изменяться от поколения к поколению, но, как правило, не претерпевает сильных изменений. Здесь в качестве примера можно привести макровирус Antisocial.F, в котором механизм кодирования и ключ к нему хранится в комментариях в коде. В процессе размножения код меняется, но также выделен в комментариях к каждому конкретному экземпляру вируса.
Различные смены названий
Разнообразные вирусы, использующие смену названий, были еще одной интересной попыткой создания полиморфного вируса. Самыми известными вирусами этой серии было семейство IIS. Так, IIS.I использовал различные методики смены названий и функций. По-видимому, автор вируса предпринял попытку изменять все обозначения, используемые в вирусном коде, но по каким-то неизвестным причинам (программные недоработки или элементарная забывчивость) не смог изменить часть из них. Вирус генерирует разнообразные имена, которые используют символы ASCII кода (от 130 до 204). Получаемый код труден для чтения и восприятия, как в приведенном примере:
If Left(+ÿ¦, 1) = "'" Then
Вирус хранит свой код в глобальном шаблоне во временных строках буфера. Там же содержится массив разнообразных имен – старых и новых, которые могут встретиться в процессе мутации. Имена выбираются из набора, хранящегося внутри вирусного кода. Существует целая серия строк-комментариев, в которых хранятся эти постоянно изменяющиеся обозначения, с соответствующими инструкциями к ним. После перебора всех имеющихся случайных обозначений, вирус генерирует новые. Новые обозначения имеют случайную длину (от 2 до 22 символов) и состоят из случайных символов ASCII с кодом в пределах от 130 до 204. Новые имена также хранятся в массиве в случайном месте
В отличие от других полиморфов, IIS.I даже осуществлял проверки для избежания конфликтов названий. Проверка проводилась по двум причинам: (обе могут вести к ошибке):
Если обнаруживалось несоответствие одному из этих требований, вирус решал проблему очень просто - генерировал новые случайные имена (а в некоторых версиях изменяя или добавляя один из символов в названии).
После того, как вирус проводил проверку и решал, что новое обозначение годится, вирус начинал поиск в буфере строчка за строчкой. Строки, содержащие свой код, вирус отмечал специальными метками из ASCII таблицы с символами менее 65. Как только вирус находил свою старую переменную, он заменял ее на новую, после чего процесс продолжался.
К полиморфным этот вирус относили только потому, что антивирусные сканеры кода или p-кода не способны были его обнаружить. Для обнаружения данного типа вирусов использовался поиск устанавливаемых вирусом меток, после чего вирус поражался его же оружием – найденные компоненты заменялись на неизвестные вирусу переменные:
If Left(var_1, 1) = "'" Then
var_2 = var_2 + 1
var_3(var_2, 1) = Mid(var_1, 2, Len(var_1))
Но тут всегда существовала опасность, что вирус мог и не записывать свой код в пустые модули, а дописывать в уже существующие (примером являются Win32 вирусы EPO viruses). В этом случае метка переменной вируса могла начинаться не с, допустим, var_1, а с var_234 и даже var_7458. В таком случае сканер должен искать четкое соответствие между названием переменной и ее нахождением в макрокоде и удалять исключительно переменные, имеющиеся в базе данных вируса. Здесь очень важно, с одной стороны, не пропустить вирусных компонентов, а с другой, очень осторожно подходить к их замене, иначе результатом будет потеря огромных массивов данных и сбой в работе основной программы, что никак не допустимо для антивирусных программ.
Заключение
В этой статье рассмотрены ранние этапы создания полиморфизма в вирусах, эволюция полиморфных макровирусов, используемые вирусные технологии и их методы обнаружения. В следующей статье будут рассмотрены первые серьезные макровирусы, которые действительно сумели достичь полиморфизма, их эволюция до настоящего времени, наблюдающиеся пути дальнейшего развития, а также метаморфы – вирусы будущего.
Один хакер может причинить столько же вреда, сколько 10 000 солдат! Подпишись на наш Телеграм канал, чтобы узнать первым, как выжить в цифровом кошмаре!

Хакерский мир можно условно разделить на три группы атакующих:
Может ли кто-то с хорошими навыками в программировании стать последним? Не думаю, что вы начнете создавать что-то, на подобии regin (ссылка) после посещения нескольких сессий DEFCON. С другой стороны, я считаю, что сотрудник ИБ должен освоить некоторые концепты, на которых строится вредоносное ПО.
Зачем ИБ-персоналу эти сомнительные навыки?
Знай своего врага. Как мы уже обсуждали в блоге Inside Out, нужно думать как нарушитель, чтобы его остановить. Я – специалист по информационной безопасности в Varonis и по моему опыту – вы будете сильнее в этом ремесле если будете понимать, какие ходы будет делать нарушитель. Поэтому я решил начать серию постов о деталях, которые лежат в основе вредоносного ПО и различных семействах хакерских утилит. После того, как вы поймете насколько просто создать не детектируемое ПО, вы, возможно, захотите пересмотреть политики безопасности на вашем предприятии. Теперь более подробно.
Кейлогер – это ПО или некое физическое устройство, которое может перехватывать и запоминать нажатия клавиш на скомпрометированной машине. Это можно представить как цифровую ловушку для каждого нажатия на клавиши клавиатуры.
Зачастую эту функцию внедряют в другое, более сложное ПО, например, троянов (Remote Access Trojans RATS), которые обеспечивают доставку перехваченных данных обратно, к атакующему. Также существуют аппаратные кейлогеры, но они менее распространены, т.к. требуют непосредственного физического доступа к машине.
Тем не менее создать базовые функции кейлогера достаточно легко запрограммировать. ПРЕДУПРЕЖДЕНИЕ. Если вы хотите попробовать что-то из ниже следующего, убедитесь, что у вас есть разрешения, и вы не несёте вреда существующей среде, а лучше всего делать это все на изолированной ВМ. Далее, данный код не будет оптимизирован, я всего лишь покажу вам строки кода, которые могут выполнить поставленную задачу, это не самый элегантный или оптимальный путь. Ну и наконец, я не буду рассказывать как сделать кейлогер стойким к перезагрузкам или пытаться сделать его абсолютно не обнаружимым благодаря особым техникам программирования, так же как и о защите от удаления, даже если его обнаружили.
Вы можете изучить больше про фунцию GetAsyncKeyState на MSDN:
Для понимания: эта функция определяет нажата клавиш или отжата в момент вызова и была ли нажата после предыдущего вызова. Теперь постоянно вызываем эту функцию, чтобы получать данные с клавиатуры:
Умный кейлогер
Погодите, а есть ли смысл пытаться снимать всю подряд информацию со всех приложений?
Код выше тянет сырой ввод с клавиатуры с любого окна и поля ввода, на котором сейчас фокус. Если ваша цель – номера кредитных карт и пароли, то такой подход не очень эффективен. Для сценариев из реального мира, когда такие кейлогеры выполняются на сотнях или тысячах машин, последующий парсинг данных может стать очень долгим и по итогу потерять смысл, т.к. ценная для взломщика информация может к тому времени устареть.
Давайте предположим, что я хочу заполучить учетные данные Facebook или Gmail для последующей продажи лайков. Тогда новая идея – активировать кейлоггинг только тогда, когда активно окно браузера и в заголовке страницы есть слово Gmail или facebook. Используя такой метод я увеличиваю шансы получения учетных данных.
Вторая версия кода:
Этот фрагмент будет выявлять активное окно каждые 100мс. Делается это с помощью функции GetForegroundWindow (больше информации на MSDN). Заголовок страницы хранится в переменной buff, если в ней содержится gmail или facebook, то вызывается фрагмент сканирования клавиатуры.
Этим мы обеспечили сканирование клавиатуры только когда открыто окно браузера на сайтах facebook и gmail.
Еще более умный кейлогер
Давайте предположим, что злоумышленник смог получить данные кодом, на подобии нашего. Так же предположим, что он достаточно амбициозен и смог заразить десятки или сотни тысяч машин. Результат: огромный файл с гигабайтами текста, в которых нужную информацию еще нужно найти. Самое время познакомиться с регулярными выражениями или regex. Это что-то на подобии мини языка для составления неких шаблонов и сканирования текста на соответствие заданным шаблонам. Вы можете узнать больше здесь.
Для упрощения, я сразу приведу готовые выражения, которые соответствуют именам логина и паролям:
Где первое выражение (re) будет соответствовать любой электронной почте, а второе (re2) любой цифро буквенной конструкции больше 6 символов.
Бесплатно и полностью не обнаружим
В своем примере я использовал Visual Studio – вы можете использовать свое любимое окружение – для создания такого кейлогера за 30 минут.
Если бы я был реальным злоумышленником, то я бы целился на какую-то реальную цель (банковские сайты, соцсети, тп) и видоизменил код для соответствия этим целям. Конечно, также, я запустил бы фишинговую кампанию с электронными письмами с нашей программой, под видом обычного счета или другого вложения.
Остался один вопрос: действительно такое ПО будет не обнаруживаемым для защитных программ?
Я скомпилировал мой код и проверил exe файл на сайте Virustotal. Это веб-инструмент, который вычисляет хеш файла, который вы загрузили и ищет его в базе данных известных вирусов. Сюрприз! Естественно ничего не нашлось.
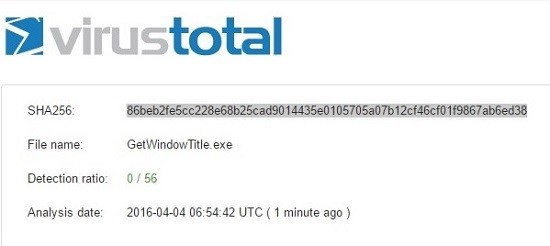
В этом основная фишка! Вы всегда можете менять код и развиваться, будучи всегда на несколько шагов раньше сканеров угроз. Если вы в состоянии написать свой собственный код он почти гарантированно будет не обнаружим. На этой странице вы можете ознакомиться с полным анализом.
Основная цель этой статьи – показать, что используя одни только антивирусы вы не сможете полностью обеспечить безопасность на предприятии. Нужен более глубинная оценка действий всех пользователей и даже сервисов, чтобы выявить потенциально вредоносные действия.
В следующих статья я покажу, как сделать действительно не обнаружимую версию такого ПО.
Наш сегодняшний разбор будет посвящен полиморфному генератору инструкций, применяемому в известном вирусе Virus.Win32.Sality.aa. Он позволяет получать различный обфусцированный код с применением FakeAPI при каждом его использовании.
Но и это еще не все. Если честно, на эту статью у нас большие планы, ведь в ней мы рассмотрим тонкости формирования x86-инструкций – префиксы, опокды, поля ModRM, SIB, и опишем признаки, по которым можно отличить обфусцированный и потенциально зловредный код от стандартного, сгенерированного обычным компилятором. Также не останутся без внимания общие схемы работы обфускатора и непосредственно генератора кода.
Он в полной мере полиморфен, код его сильно и качественно обфусцирован, а также снабжен антиэмуляцией на основе вызова API–функций
Ликбез: полиморфизм и обфускация
PUSH 0; POP EAX;
XOR EAX, EAX;
MOV EAX, 0;
AND EAX, 0;
В этом и заключается полиморфизм – сделать одно и то же, только разными способами.
Обфускация – приведение исходного текста или исполняемого кода программы к виду, сохраняющему ее функциональность, но затрудняющему анализ, понимание алгоритмов работы и модификацию при декомпиляции. Конкретный пример:
PUSHAD; NOP; NOP; NOP; NOP; POPAD;
ADD EAX, 0xFFEEFFEE; INC EAX; OR EAX, EAX; SUB EAX, 0xFFEEFFEF;
PUSH EBX; PUSH ECX; POP ECX; POP EBX; LEA EAX, [EAX]; MOV EDX, EDX;
Схема заражения PE-файла вирусом Virus.Win32.Sality.aa
Перейдем непосредственно к генератору. В его задачу входит формирование кода с заданными свойствами, определенного размера и выполняющего заданный псевдокод. Так каким же образом работает генератор? В общем случае алгоритм выглядит следующим образом:
Схема, отражающая алгоритм работы полиморфного генератора
Поясним приведенную схему. На самом начальном этапе генератор получает на вход так называемый псевдокод, который содержит логику исполняемого фрагмента. Псевдокод представляет собой совокупность команд, отражающих определенную функциональность и понятных для человека. Далее происходит компиляция, причем полученный машинный код получается каждый раз разными способами. В этом и заключается полиморфизм. После этого машинный код подвергается обфускации, опять-таки с использованием генератора случайных чисел. И начатое дело завершается добавлением одной или нескольких фэйковых API-функций в код. Каждый этап по-своему интересен и будет рассмотрен довольно подробно прямо сейчас.
- Сохранить оригинальные значения регистров и флагов;
- Получить VA текущего;
- Вычислить VA перехода;
- Выполнить переход по вычисленному VA.
Третий и четвертый этапы, в отличие от первого и второго, реализуются в Sality множеством способов. В последних используются соответственно инструкции PUSHAD и CALL. Вызов PUSHAD нужен, чтобы сохранить исходное состояние процессора, и чтобы перед тем, как передать управление оригинальной программе, можно было вызвать инструкцию POPAD, восстанавливающую оригинальные значения регистров. А вызов команды CALL, помимо выполнения перехода, кладет в стек виртуальный адрес (VA) следующей инструкции. Для вычисления адреса перехода используется значение, полученное на втором этапе. Способов вычисления очень много. Приведем некоторые из них (будем считать, что адрес, полученный на втором этапе, располагается на вершине стека):
POP REG;
SUB REG, IMM;
MOV REG, [ESP];
ADD REG, IMM;
ADD [ESP], IMM;
POP REG;
В приведенных выше примерах и далее по тексту под REG подразумевается любой 32-битный регистр общего назначения, а под IMM – числовое значение любой размерности. Самый последний этап (четвертый) также может быть выполнен по-разному (считаем, что в REG находится необходимый Sality адрес назначения):
Стартовый код Virus.Win32.Sality.aa в зараженном файле
Теперь перейдем к обзору обфускации. Как видно из дизассемблерных листингов, представленных на иллюстрациях, большинство инструкций не несут полезной нагрузки, а добавлены только для того, чтобы усложнить анализ. Красными овалами выделены инструкции, соответствующие всем этапам псевдокода. В данном файле вычисление адреса для перехода реализуется аж семью командами.
Сам обфускатор работает в несколько этапов, получая на входе определенные параметры, задающие возможный вид получаемой команды, а на выходе – готовую инструкцию:
- генерация опкода из списка (одно- или двух- байтовый опкод);
- генерация байта ModRM;
- добавление произвольного числового операнда;
- добавление префикса к полученной инструкции.
Формат инструкции архитектуры x86
Итак, каждая инструкция обязана включать в себя опкод. Он может быть как однобайтовый, так и двух- и трехбайтовый. Если первый байт опкода равен 0Fh, то он является двухбайтовым. Для трехбайтовых возможно несколько вариантов, но это не будет затронуто в статье. Каждый опкод обладает определенными свойствами. Например, 0B8h – MOV eAX, lz, использует следующие четыре байта, добавляя их к инструкции. Таким образом получается, что последовательность байт B8 FF FF FF FF эквивалентна инструкции MOV EAX, 0FFFFFFFFh. Существуют опкоды, которые сами по себе образуют инструкцию, например, PUSH EBP – 55h, PUSHAD – 60h. А есть такие опкоды, в которых следующий байт несет определенный смысл и называется ModRM.
Этот байт состоит из трех полей, показанных на схеме: Mod, Reg/Opcode, R/M. С помощью Mod’а определяется тип операнда, используемого инструкцией – память или регистр. Если его значение равно 3, то это регистр, а остальные возможные – память. Основное назначение R/M и Reg/Opcode – указывать на операнды инструкции. А для некоторых опкодов, например, 0x80, 0x81, 0xC1, поле Reg/Opcode указывает на саму операцию, выполняемую инструкцией. Если в инструкции поле Mod не равно 3, и в то же время поле R/M равно 4, то появляется еще один байт – SIB. Он также показан на схеме. Он используется для формирования инструкций, работающих с составными операндами памяти. Например: ADD EAX, [EAX + ECX*4 + 600].
Еще одним необязательным элементом, образующим инструкцию является префикс. Каждый префикс занимает один байт. Но у команды может быть сразу несколько префиксов. Они используются для придания инструкции определенных свойств. Всего их одиннадцать:
F0 – Lock; F2 – REPNE; F3 – REP; 2E – CS segment override; 36 – SS - // - // -; 3E – DS - // - // -; 26 – ES - // - // -; 64 – FS - // - // -; 65 – GS - // - // -; 66 – Operand – Size; 67 – Address Size;
Согласно документации Intel каждый префикс может использоваться только в определенных целях, хотя, безусловно, их можно вручную добавить к произвольной команде. Все сегментные префиксы используются совместно с инструкциями, работающими с памятью, для обращения к определенному сегменту. А байты REPNE/REP добавляются только к инструкциям, работающим со строками или с массивом байт, к примеру – SCASB, MOVSD, LODSW. Префиксы размеров операнда и адреса изменяют соответственно их размеры на меньший или больший, в зависимости от режима работы.
Так что же использует генератор Sality? Во-первых, он использует однобайтовые опкоды, целиком образующие инструкцию. К ним относятся все PUSH’ы и POP’ы. Во–вторых, во всех генерируемых инструкциях поле Mod равно 3, чтобы избежать взаимодействия с памятью, а оперировать только с другими регистрами или мгновенными значениями. Исключение составляет команда LEA, в которой Mod всегда равен 2, а использование 3 приведет к генерации исключения. В-третьих, используется множество двухбайтовых опкодов, которые опять-таки не оперируют с памятью: SHLD, BSF, BTS, BTC, XADD и др. И напоследок – Sality добавляет байт 66h, а также сегментные и REPxx префиксы к произвольным инструкциям. С помощью всех этих методов получается качественный обфусцированный код, который не взаимодействует с памятью, но при этом значительно усложняет анализ кода.
А теперь можно обсудить и те моменты, которые позволяют отличить сгенерированный код от кода, полученного компилятором. Начнем с префиксов. Генератор в Sality добавляет их к совершенно произвольным инструкциям. А в документации Intel написано следующее:
Таким образом, использование префиксов F2 и F2 возможно лишь с ограниченным списком инструкций, а в приведенном выше примере кода эти байты находятся перед командами CALL, SHL, TEST и прочими. Аналогичная ситуация и с сегментными префиксами. Их использование не по назначению может носить неопределенный характер. А в Sality байт 64h может без проблем предварять инструкцию CALL. Компилятор при генерации кода никогда не будет добавлять префиксы к тем командам, к которым это запрещено делать!
На что еще следует обратить внимание при просмотре кода? Например, на практически полное отсутствие работы с памятью, а значит, и отсутствие локальных и глобальных переменных. Это весьма странно, так как компилятор может использовать только регистры в коротких функциях, и то при определенных условиях. Еще одна особенность полученного кода – совершенно произвольные числовые операнды. Такое, конечно, иногда бывает, когда реализуется какая–то функция из криптоалгоритма, но даже в ней нет такого обилия случайных чисел.
Переходим к самому последнему этапу генерации кода – добавление FakeAPI. Этот метод используется для обхода простых эмуляторов или виртуальных машин. А заключается он в вызове произвольной API – функции, в надежде на то, что эмулятор не поддерживает работу с таблицей импортов или не может реализовать корректное исполнение. В представленном дизассемблерном листинге в таком качестве используются две функции – FindClose и GetModuleHandleA. В представленном случае очень легко отличить фэйковые запуски от реальных вызовов. Во-первых, результат их работы – регистр EAX или его составные части, впоследствии просто стираются и не используются, что довольно странно для нормальной программы. Во-вторых, функции FindClose должен передаваться корректный хэндл, полученный ранее с помощью FindFirstFile. А в приведенном файле происходит исполнение FindClose (0) прямо с точки входа, что явно не может иметь место в нормальном файле. Генератор, при добавлении FakeApi в конечный код, пользуется определенным списком, в котором перечислены API-функции, которые получают на вход только один параметр и не вносят никаких значительных изменений в систему.
Заключение
В коллекции вредоносных Android-приложений некоторых антивирусных лабораторий содержится уже более 10 миллионов образцов. Эта цифра будоражит воображение, но примерно 9 миллионов 995 тысяч из них — переименованные копии оригинальных вирусов. Но если проанализировать исходный код оставшихся нескольких тысяч образцов малвари, то можно заметить, что все они комбинируются из небольшого количества уникальных функциональных блоков (несколько видоизмененных и по-разному скомбинированных).
Все дело в том, что вирмэйкеры чаще всего преследуют весьма тривиальные задачи:

Другие статьи в выпуске:
Далее приведен простейший пример кода. Это элементарная функция отправки SMS. Ее можно усложнить проверкой статуса отправки, выбором номеров в зависимости от места положения абонента и последующим удалением SMS.
Где искать код вируса
В абсолютном большинстве случаев заражение телефона происходит через установку приложений. Любое приложение для Android существует в виде файла с расширением apk, который, по сути, является архивом. Просмотреть его содержимое можно с помощью Android SDK, конвертера файлов APK в JAR и декомпилятора Java-байт-кода. Сборка приложения (APK) состоит из следующих частей:
- resources.arsc — таблица ресурсов;
- res (папка) — собственно ресурсы (иконки и прочее);
- META-INF (папка) — содержит файлы со следующим содержимым: контрольные суммы ресурсов, сертификат приложения и описание сборки APK;
- AndroidManifest.xml — всякого рода служебная информация. В том числе разрешения (permission), которые приложение запрашивает перед установкой для своей корректной работы;
- classes.dex — ты наверняка слышал, что в Android операционных системах весь код выполняется с помощью Dalvik virtual machine (начиная с версии 4.4 появляется поддержка ART), которая не понимает обычный Java-байт-код. Поэтому и существуют файлы с расширением dex. В нем, наряду с нужными и полезными классами (которые отвечают за функционал приложения), содержатся также и вредоносные (вирусный код, который мы разбираем в этой статье).
SMS зараженных юзеров особенно ценны номерами телефонов отправителей и получателей — ими можно пополнить базу для спам-рассылок. Реже вирусы такого рода используются для заражения устройств конкретных личностей — в следующий раз, когда твоя девушка предложит тебе протестировать написанное ей (ай, карамба! — Прим. ред.) приложение на Android, не теряй бдительности :).
- DroidKungFu;
- DroidDream;
- подавляющее большинство малвари всех аналогичных.
В принципе, любому вирусмейкеру полезна информация о зараженных его программами устройствах. Получить ее очень просто. Создается массив с данными о свойствах телефона (их полный список можно посмотреть в руководстве Android-разработчика) и отправляется POST-запросом к PHP-скрипту (язык непринципиален) на сервере злоумышленника, тот обрабатывает данные и помещает их в базу данных для последующего использования.
- DroidKungFu;
- DroidDream;
- RootSmart.
Одна из самых неприятных вещей, которая может произойти с Android-устройством, — это его рутинг вирусом. Ведь после этого зловредная программа может делать с ним что угодно: устанавливать другие вирусы, менять настройки аппаратного обеспечения. Совершается это действо путем последовательного запуска эксплойтов:
Сайты о мобильной малвари
Блог экспертов компании Kasperskiy Lab Этот ресурс содержит качественные и подробные статьи о многих аспектах компьютерной безопасности, в том числе и об Android-вирусах. Стоит регулярно посещать этот сайт, чтобы быть в курсе последних событий.
Androguard Google Group Группа посвящена open source инструменту для всевозможных манипуляций с кодом Android-приложений (декомпиляция и модификация DEX/ODEX/APK файлов и так далее). Androguard также содержит обширную базу статей про вирусы. Помимо кратких обзоров функционала и методов защиты, встречаются подробные анализы кода малвари.

Androguard Google Group
Защита от вирусов
Как мы видим из примеров, мобильный вирмейкинг технологической сложностью не отличается. Конечно, данные примеры упрощены под формат журнала — прежде всего, упущены обработчики ошибок и исключений, а также отдельные технические мелочи, отсутствие которых не помешает тебе понять принципы работы Android-малвари, но оградит от ненужных экспериментов. Ведь мы не поддерживаем создание вирусов, не так ли? 🙂
Вирусы стали неотъемлемой частью нашей компьютерной (и не только) жизни. На написание данной статьи меня подтолкнуло то, что, на мой взгляд, в Сети маловато информации, наиболее полно раскрывающей весь процесс написания вируса. Совсем недавно мне необходимо было написать простую самораспространяющуюсю программу, которая не производила бы каких-либо вредных для системы действий, но в то же время использовала бы вирусные механизмы распространения. Скажу, что все-таки в Интернете есть информация на эту тему. И даже встречаются исходники подобных программ. Но во всем приходится долго и упорно разбираться, если хочешь сделать что-то сам. Итак, в чем-то более-менее разобравшись, я хочу поделиться с вами - читателями - информацией.
В данной статье будет рассмотрен процесс написания простого вируса, заражающего исполняемые файлы формата PE (Portable Executable) EXE. Также напишем программу-доктора, которая ищет в указанной директории и во всех поддиректориях файлы, зараженные нашим вирусом.
Данная самораспространяющаяся программа не содержит в себе никакого вредоносного кода, но ее с легкостью можно дописать до вполне боевого вируса. Поэтому хочу заметить, что
ВСЕ ПРИВЕДЕННОЕ В ЭТОЙ СТАТЬЕ МОЖЕТ БЫТЬ ИСПОЛЬЗОВАНО ТОЛЬКО В УЧЕБНО-ПОЗНАВАТЕЛЬНЫХ ЦЕЛЯХ. Автор не несет никакой ответственности за любой ущерб, нанесенный применением полученных знаний.
Если вы с этим не согласны, то, пожалуйста, прекратите чтение этой статьи и удалите ее со всех имеющихся у вас носителей информации.
Кратко о формате PE
Поскольку наш вирус будет заражать именно PE-файлы, мы, естественно, должны иметь представление об этом формате. Это формат исполняемых в операционной системе Windows файлов. Кстати, раз уж мы заговорили об ОС, то заметим, что наш вирус должен нормально исполняться на как можно большем числе ОС данного семейства. Программа тестировалась на работоспособность в Win
9x\Me\NT\2000\XP\2K3.
Итак, если заглянуть внутрь типичного исполняемого файла, мы увидим следующую структуру в упрощенном виде:

PE-файл в самом своем начале (MZ-заголовок) содержит программу для ОС DOS. Эта программа называется stub и нужна для совместимости со старыми ОС. Если мы запускаем PE-файл под ОС DOS или OS/2, она выводит на экран консоли текстовую строку, которая информирует пользователя, что данная программа не совместима с данной версией ОС. Программист при линковке может указать любую программу DOS, любого размера. После этой DOS-программы идет структура, которая называется IMAGE_NT_HEADERS (PE-заголовок). Эта структура описывается следующим образом:
Первый элемент IMAGE_NT_HEADERS – сигнатура PE-файла. Для PE-файлов она должна иметь значение "PE\0\0". Далее идет структура, которая называется файловым заголовком и определенная как IMAGE_FILE_HEADER. Файловый заголовок содержит наиболее общие свойства для данного PE-файла. После файлового заголовка идет опциональный заголовок - IMAGE_OPTIONAL_HEADER32. Он содержит специфические параметры данного PE-файла. После опционального заголовка начинается таблица секций (Object Table). В ней содержится информация о каждой секции. После таблицы секций идут исходные данные для секций. В конец PE-файла можно записать любую информацию и от этого функционирование программы не изменится (если там не присутствует проверка контрольной суммы или что-то подобное).
Способы заражения PE
До сих пор мы ничего не сказали о том, каким способом будем заражать файл, ведь их несколько:
- Внедрение в PE-заголовок
- Расширение последней секции
- Добавление новой секции
Для нашего учебного вируса подойдет наиболее простой метод расширения последней секции. Сразу скажу, что большими недостатками последних двух методов является то, что размер файла-жертвы заметно увеличивается при заражении, т.к. мы дописываем код вируса в конец файла. Хотя оговорюсь, что при втором методе возможно извратиться так, чтобы можно было записываться в пустой оверлей в конце последней секции, поэтому размер файла может измениться незначительно, либо не измениться вообще. При первом же методе размер файла не изменяется, но недостаток такого метода - не всегда можно найти такой EXE, чтобы в его заголовке хватило места для кода нашего вируса. Приходится либо заражать очень малое количество программ, либо сильно ограничивать возможности нашего вируса, т.к. это уменьшает размер его кода. Метод добавления новой секции немного сложнее, поэтому его рассматривать не будем. Скажу только, что файл с какой-нибудь новой секцией будет выглядеть более подозрительно.
Нам для написания нашего вируса достаточно знать, что при заражении файла мы должны
изменить некоторые значения (какие - прочитаем ниже) в PE-заголовке, изменить дескриптор последней секции, добавить код нашего вируса в конец последней секции, а также изменить точку входа программы так, чтобы управление при ее запуске передавалось сначала нашему вирусу, а уж затем - самой программе. На следующем рисунке красным цветом отмечены те части файла, которые будут изменены при заражении:

Вычисляем дельта-смещение
Итак, мы приняли решение дописываться в конец исполняемого файла. Прежде, чем приводить код, отмечу, что для начала нам нужно найти адреса необходимых API-функций. Разберемся сейчас с наиболее важными понятиями: Virtual Address (VA) и Relative Virtual Address
(RVA).
VA - это адрес чего-нибудь в оперативной памяти. RVA - это смещение на что-то относительно того места, куда проецирован файл. А если просто сказать, то VA = RVA + база.
Чтобы наш вирус работал, он должен быть написан в базонезависимом коде. В связи с этим появляется еще одно понятие - дельта-смещение.
Что это такое? Все очень просто. Когда вирус находится в чистом виде (так называемое первое поколение), т.е. не записан еще ни в какой файл, когда он работает, он обращается к переменным как есть относительно прописанного в его заголовке адреса, куда файл проецирован системой. Теперь представим, что наш вирус заразил программу. И там начинает работать. Но теперь он работает не там, куда его загрузил загрузчик, а из того места, где находится загруженная зараженная программа. Получается, что переменные теперь указывают на абсолютно другое место. Поэтому обратившись к своим данным по заданным адресам, вирус прочитает совсем не те данные, которые ему необходимы. Для того, чтобы решить эту проблему, вычисляется
дельта-смещение. Это смещение относительно начала вируса, а не той программы, которая была им заражена.
Как видим, при входе в вирусный код мы вызываем call. Но call после вызова помещает в стек адрес возврата. Вычитаем из него адрес метки VirDelta и получаем нужное нам смещение относительно начала файла. Далее сохраняем дельта-смещение для дальнейшего использования (прибавляя его к адресам переменных, последние принимают корректные значения).
Ищем адреса API-функций
Следующая проблема состоит в поиске этих самых адресов. Но для начала нужно найти адрес библиотеки kernel32.dll в памяти, т.к. самые необходимые функции находятся именно в ней. Если нам потребуется использовать функции из других библиотек, мы просто используем LoadLibrary и GetProcAddress, которые находятся в kernel32.dll.
Существует множество методов поиска базы kernel32, один из которых - использование механизма структурной обработки исключений SEH (Structured Exception
Handling).
SEH представляет собой цепочку обработчиков - ячейки памяти, в которых содержатся адреса на процедуры обработки исключений. Эта цепочка начинается с fs:0000 и заканчивается последним обработчиком, который содержит значение 0FFFFFFFFh. Ну и что это нам дает? А то, что адрес последнего обработчика - это и есть адрес kernel32.dll в памяти.
Итак, дельта-смещение мы определили. Приведем теперь код поиска базы kernel32:
Здесь мы сканируем память (с того адреса, который мы только что получили) на наличие сигнатуры MZ (4D5Ah). Если она присутствует, значит, все сделано верно. Далее по смещению 3Ch находится смещение начала PE-заголовка. Сравниваем значение 2х байтов по этому смещению на сигнатуру PE (5045h) (на случай, если мы чисто случайно попали на ту область памяти, где нам встретились символы MZ). Если значение этих байт равно PE, то kernel32.dll несомненно найдена.
Теперь рассмотрим некоторые поля PE-заголовка, необходимые нам:

Чтобы найти адрес необходимой нам API-функции в kernel32, нам нужно добраться до секции экспорта этой библиотеки. По смещению 78h от начала PE-заголовка находится RVA адрес этой секции. Но не забудем, что нам нужен не RVA, а VA. Для этого нужно сложить этот RVA со значением Image Base (адрес в области памяти, куда файл проецирован системой). Тогда мы получим реальный адрес секции экспорта.
Наверняка при просмотре таблицы может возникнуть вопрос: а что это за поле Win32VersionValue? Это поле загрузчиком не используется вообще, поэтому мы можем считать его резервным и записывать какую-то информацию. В дальнейшем будем использовать данное резервное поле для записи сигнатуры нашего вируса, чтобы не заражать уже зараженные нашим вирусом программы.
Теперь нам нужно получить адрес таблицы экспорта из секции экспорта. Рассмотрим некоторые интересные нам поля секции экспорта:

Первое поле содержит базу ординалов функций. Второе поле содержит число указателей на имена. Третье поле содержит RVA таблицы экспорта. Эта таблица содержит адреса экспортируемых функций (их точки входа) или данных в формате DWORD RVA (по 4 байта на элемент). Четвертое поле - RVA таблицы указателей на имена. Последнее поле - RVA на таблицу ординалов. Для доступа к данным используется ординал функции с коррекцией на базу ординалов (Ordinal
Base).
Итак, теперь мы знаем адрес таблицы имен и адрес таблицы адресов всех функций библиотеки kernel32.dll. Чтобы найти адрес конкретной функции, мы должны сравнить ее имя с каждым именем в таблице имен экспортируемых функций, и если очередное сравниваемое имя совпало с искомым, мы смотрим в таблицу ординалов по соответствующему индексу и извлекаем таким образом адрес функции. Далее нам этот адрес остается где-то сохранить (в нашем случае – в стеке) для дальнейшего использования и перейти к поиску адреса другой нужной нам функции и так далее.
Чтобы не хранить в коде вируса имена функций (ведь они бывают иногда длинные), нам достаточно хранить 4-байтовые хеш-значения имен. Заодно и при просмотре тела вируса в HEX-редакторе не бросаются в глаза имена функций, содержащиеся в коде вируса:
А при поиске нужной нам функции мы будем сравнивать не имена, а хеш-значения имен (подсчитав предварительно это значение для каждой нужной нам функции). Т.е., допустим, что мы нашли какое-то имя в таблице имен kernel32. Вычисляем хеш-значение этого имени и сравниваем это значение с искомым из нашей таблицы хешей HashTable. Если совпадают – значит, нашли. Если нет – ищем
дальше:
Но как нам вычислить заранее хеш-значение определенного имени? Для этого я написал небольшую программку на Visual C++ с ассемблерной вставкой, ссылку на которую можно найти в конце статьи (с исходником).
После выполнения приведенного кода адреса всех функций будут находиться в стеке:
Общая структура вирусного кода
Все вышесказанное было лишь прелюдией в процессе написания нашего вируса. Теперь начнется самое интересное. Будем писать вирус на MASM. Почему я отдаю предпочтение этому пакету? Просто он мне нравится.
Напишем общий файл main.asm, который будет включать отдельные части кода:
В файле start_code.inc содержится весь приведенный ранее код по определению дельта-смещения, поиску базы kernel и адресов функций. Содержимое остальных файлов будет ясно из дальнейшего изложения. Но в любом случае в конце статьи есть ссылки с полностью рабочими примерами и исходниками.
Смотря на этот код, можно задать как минимум два вопроса:
- зачем нам макрос szText?
- зачем подключать библиотеку kernel32.lib и вызывать функцию ExitProcess перед начальной меткой?
Хитрый макрос позволяет нам не хранить текст в переменной, а сразу заталкивать его адрес в стек перед вызовом какой-либо функции, имеющей одним из своих параметров текстовую строку. Например, в функцию
LoadLibrary:
Что же касается вызова функции ExitProcess, то здесь проблема кроется в системах старше Windows XP (Win9x\Me\NT\2000). При попытке запустить код без такого вызова программа попросту не запускалась в перечисленых системах. Причем молча. Скорее всего, это связано с тем, что в данных системах загрузчик не хочет загружать программы без секций импорта. Не будем отвлекаться от нашей темы, поскольку исследование данного вопроса выходит за рамки этой статьи.
Читайте также: